
The ChatGPT API Playground is a web-based platform designed to allow developers to explore the functionality of OpenAI’s cutting-edge language models. It combines swift operation with an intuitive, easy-to-use interface. It offers access to a variety of robust AI utilities, including:
- generating text,
- translating languages,
- summarizing text,
- analyzing sentiment,
We’ve previously discussed how to obtain the ChatGPT API Key in one of our earlier articles. In this piece, we will delve deeper into the ChatGPT API Playground to examine some of its principal features.
Registering Account
First step you need to do is to create an account on the OpenAI website. Just navigate to https://platform.openai.com/ and click SignUp link. You will be able to use your e-mail for registration or use Google / Microsoft / Apple account.
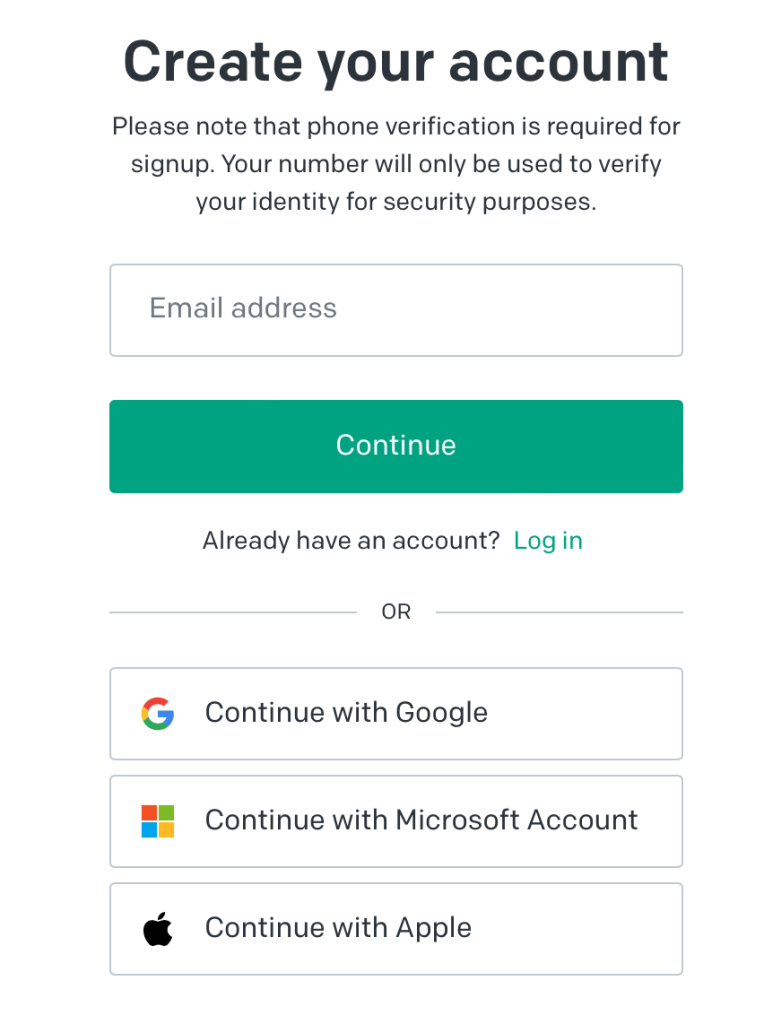
Please note that phone verification is required for signup. Your number will only be used to verify your identity for security purposes.
After successful registration you will be redirected to Platform Overview page.
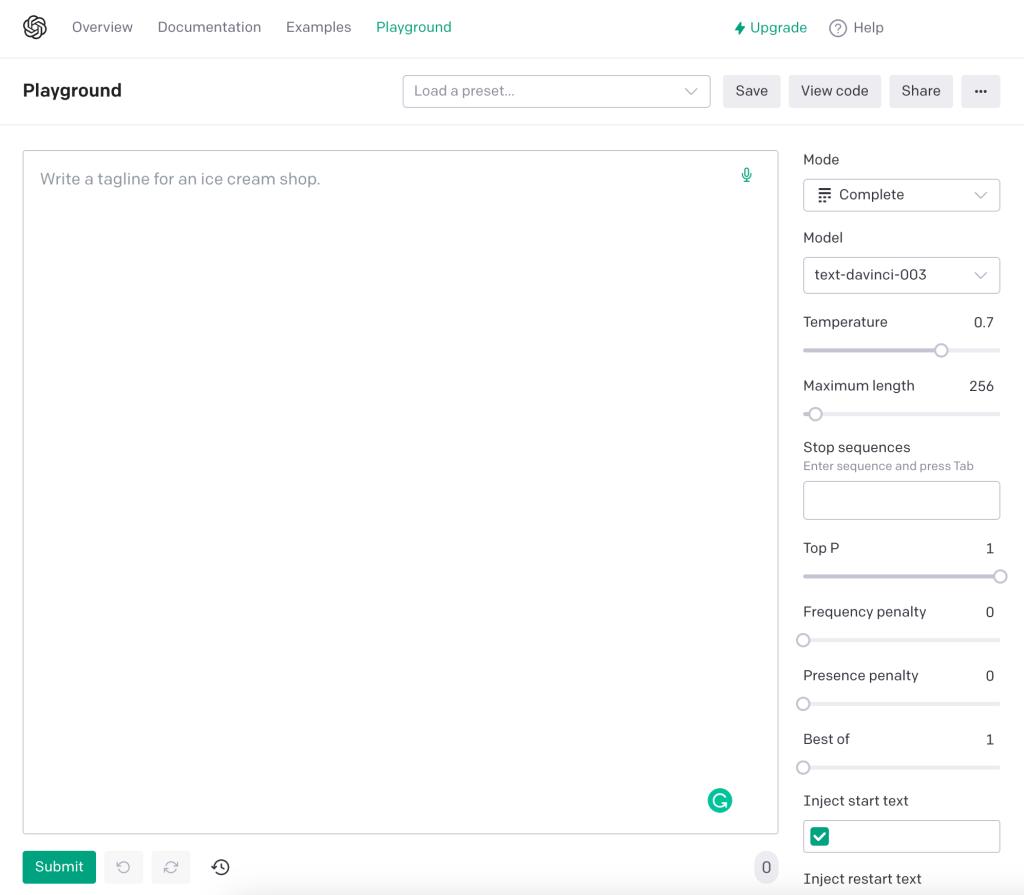
To navigate to the API Playground page, simply select the corresponding menu item located at the top-left of the screen. Once on this page, you can input a command or choose a preset, and observe how the API generates a completion that aims to align with the context or pattern you’ve specified.
You also have the option to dictate the model that processes your request by adjusting the model selection.
ChatGPT API Playground
Before you commence using the API Playground, bear these points in mind:
- Exercise discretion when disseminating outputs, and credit them to your personal or business name.
- The requests submitted to our models may be harnessed to educate and enhance future models.
- OpenAI’s standard models have a knowledge cut-off in 2021, hence they might not be updated on recent developments.
The interface of OpenAI Platform’s Playground is divided into two core sections: the data input section and the prompt settings section.
Mode
There are four available Modes as of today (May 2023):
- Complete mode,
- Chat mode,
- Insert mode,
- Edit mode.
Depending in selected mode, both areas may change UI. In this article we will be using Com
Let’s review other Settings options.
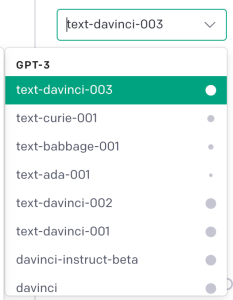
Model
There are three Models available: GPT-3 or Codex.
GPT-3 – a set of models that improve on GPT-3 and can understand as well as generate natural language or code.
Codex – a set of models that can understand and generate code, including translating natural language to code
Below you can find explanation for some of the available Models:
| Model | Details |
|---|---|
| text-davinci-003 | Can do any language task with better quality, longer output, and consistent instruction-following than the curie, babbage, or ada models. Also supports inserting completions within text. |
| text-davinci-002 | Similar capabilities to text-davinci-003 but trained with supervised fine-tuning instead of reinforcement learning |
| code-davinci-002 | Optimized for code-completion tasks |
| gpt-3.5-turbo | Most capable GPT-3.5 model and optimized for chat at 1/10th the cost of text-davinci-003 (should be added soon to the list). |
| gpt-4 | Not available yet in Playground |
Full OpenAI models list you can find on Models page.
Temperature
Controls randomness: Lowering results in less random completions. As the temperature approaches zero, the model will become deterministic and repetitive.
Possible values: [0 .. 1] with step 0.01.
Maximum length
The maximum number of tokens to generate. Requests can use up to 2,048 or 4,000 tokens shared between prompt and completion. The exact limit varies by model. One token is roughly 4 characters for normal English text)
Possible values: [1 .. 4000] with steep 1.
Stop sequences
Up to four sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence.
Top P
Controls diversity via nucleus sampling: 0.5 means half of all likelihood-weighted options are considered.
Possible values: [0 .. 1] with step 0.01.
Frequency penalty
How much to penalize new tokens based on their existing frequency in the text so far. Decreases the model’s likelihood to repeat the same line verbatim.
Possible values: [0 .. 2] with step 0.01.
Presence penalty
How much to penalize new tokens based on whether they appear in the text so far. Increases the model’s likelihood to talk about new topics.
Possible values: [0 .. 2] with step 0.01.
Best of
Generates multiple completions server-side, and displays only the best. Streaming only works when set to 1. Since it acts as a multiplier on the number of completions, this parameters can eat into your token quota very quickly – use caution!
Possible values: [1 .. 20] with step 1.
Inject start text
Text to append after the user’s input to format the model for a response.
Inject restart text
Text to append after the model’s generation to continue the patterned structure.
Show probabilities
Toggle token highlighting which indicates how likely a token was to be generated. Helps to debug a given generation, or see alternative options for a token.
Possible options:
- Off,
- Most likely,
- Least likely,
- Full spectrum.
Integration with an App
Click the “View code” button.
You can use the following code to start integrating your current prompt and settings into your application.
